US Firework Sales and Injuries (Part 1)
Data Collection and Cleaning


Notebook Created by: David Rusho (Github Blog | Tableau | Linkedin)
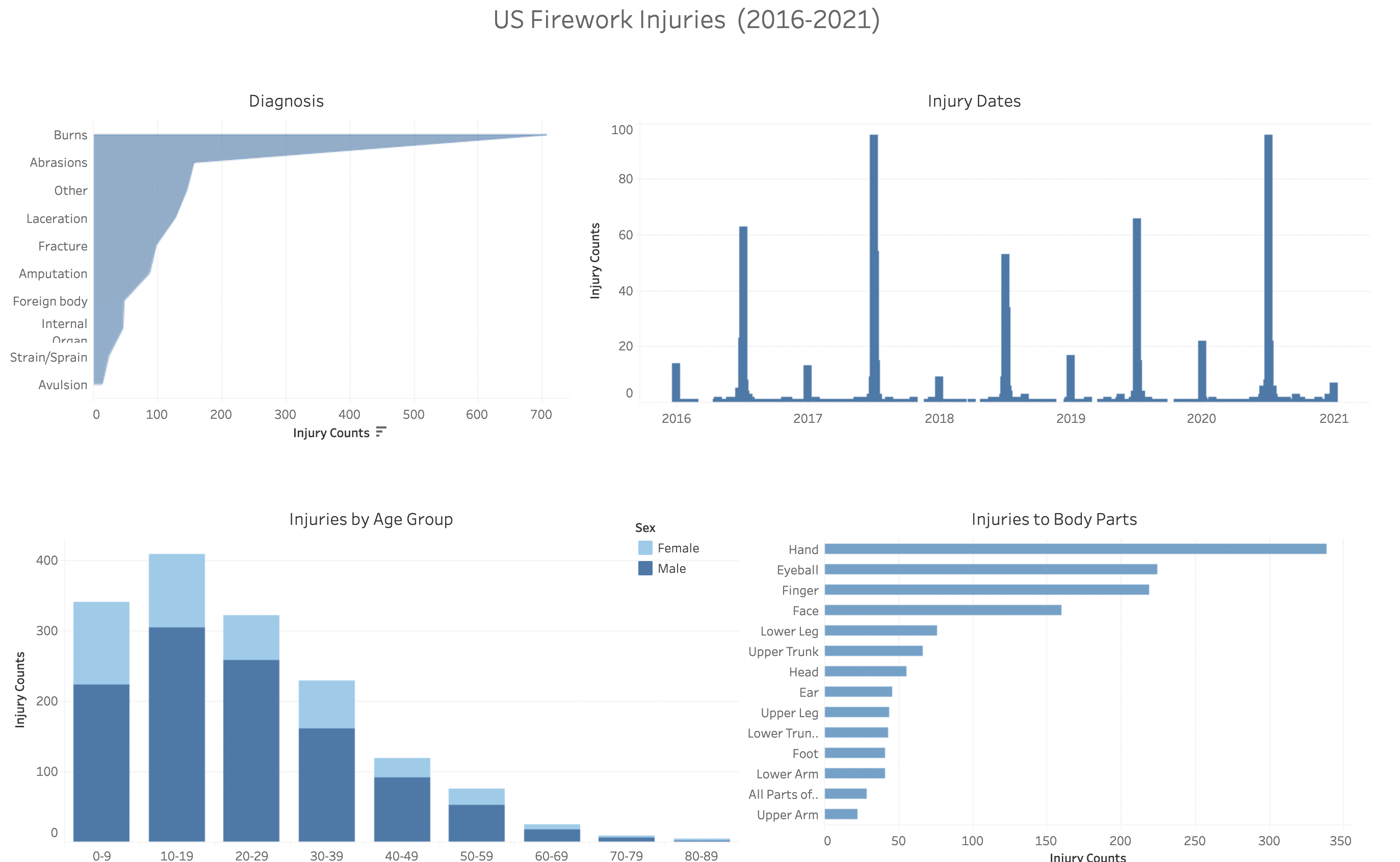
Tableau Dashboard: US Fireworks Inuries (2016-2021)
About the Data
Source: Firework Injury Reports
The following notebook represents steps that were taken to organize and clean 5 excel files that consist of incident reports involving fireforks over the past 5 years from the CPSC (United States Consumer Product Safety Commision).
The data needed to be converted to csv since reading excel into pandas is extremely slow. CSV did create larger files but the trade off for increased reading speeds was worth it. This was done manually through Excel and then exporting each file as a csv. If there were more files a more "pythonic" method would have been used to save time.
import pandas as pd
filelist = ['NEISS_2016.csv','NEISS_2017.csv','NEISS_2018.csv','NEISS_2019.csv','NEISS_2020.csv']
df = pd.concat(map(pd.read_csv, filelist))
df.head(3)
df.info()
df1 = df.query('(Product_1 == 1313) | (Product_2 == 1313) | (Product_3 == 1313)')
df1.info()
# reduce df size and clean na values
df2 = df1[['Treatment_Date','Age','Sex','Body_Part','Diagnosis','Disposition','Location','Alcohol','Drug','Narrative']].fillna('').reset_index(drop=True)
df2.head()
# Fix Sex columns
df2.Sex = df2.Sex.replace(1,"Male").replace(2,"Female")
df2.head(2)
local_df = pd.read_pickle('df_incident_local.pkl')
local_df
# fix Incident Locale
df3 = pd.merge(df2, local_df, left_on='Disposition', right_on='Code').drop(['Code','Location'],axis=1)
df3.sample(3)
body_part_df = pd.read_pickle('df_body_part.pkl')
body_part_df
# fix Body Part
df4 = pd.merge(df3, body_part_df, left_on='Body_Part', right_on='Code').drop(['Code','Body_Part_x'],axis=1)
df4.rename(columns={'Body_Part_y':'Body_Part'},inplace=True)
df4.sample(3)
# import Diagnosis pkl
diagnosis_df = pd.read_pickle('df_diagnosis.pkl')
diagnosis_df
# fix Diagnosis
df5 = pd.merge(df4, diagnosis_df, left_on='Diagnosis', right_on='Code').drop(['Code','Diagnosis'],axis=1)
df5.rename(columns={'Diagnosis1':'Diagnosis'},inplace=True)
df5.sample(3)
# import Disposition pkl
disposition_df = pd.read_pickle('df_disposition.pkl')
disposition_df
# fix Disposition
df6 = pd.merge(df5, disposition_df, left_on='Disposition', right_on='Code').drop(['Code','Disposition_x'],axis=1)
df6.rename(columns={'Disposition_y':'Disposition'},inplace=True)
df6.sample(3)
df6.to_csv('injury_clean.csv')